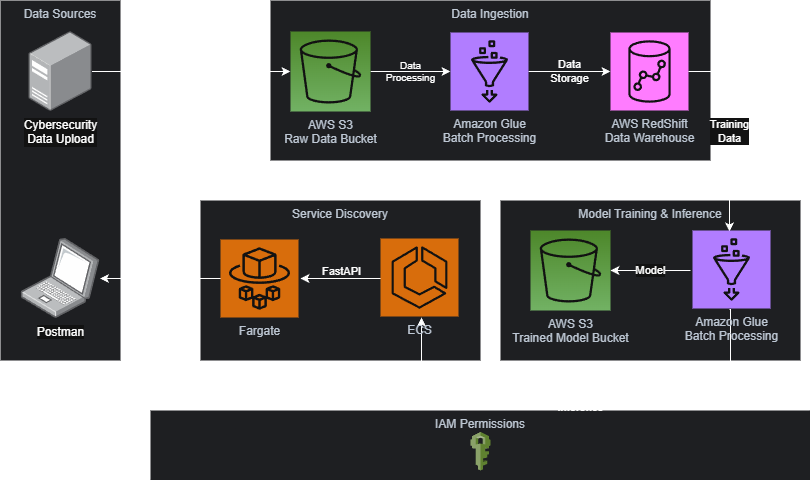
Cloud-Based Intrusion Detection System
Scalable ETL pipeline and real-time inference API processing 2.5M+ records using AWS Glue, Redshift, and ECS Fargate.
System Demo & API Inference
Short demo of the containerized FastAPI inference service running on ECS Fargate. The video shows a Postman request and the model response.
Automated Data Ingestion & Transformation
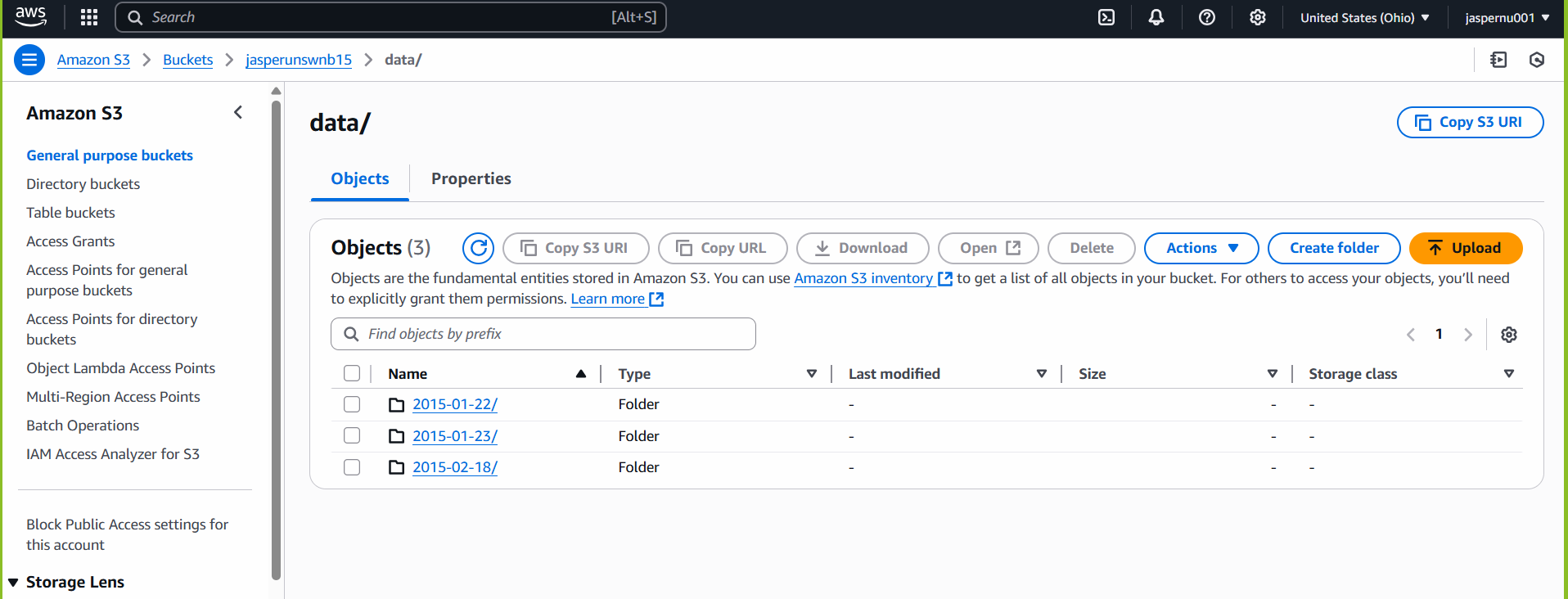
Implemented Hive-style partitioning (date=YYYY-MM-DD) in S3 to enable partition pruning and optimize query performance for daily data loads (~200MB/day). Utilized AWS Glue Crawlers for automated schema discovery to handle data drift, while PySpark ETL scripts orchestrated by AWS Glue clean, normalize, and transform raw PCAP CSV data into a Redshift-ready schema. Jobs are idempotent, versioned, and emit structured job metrics to CloudWatch.
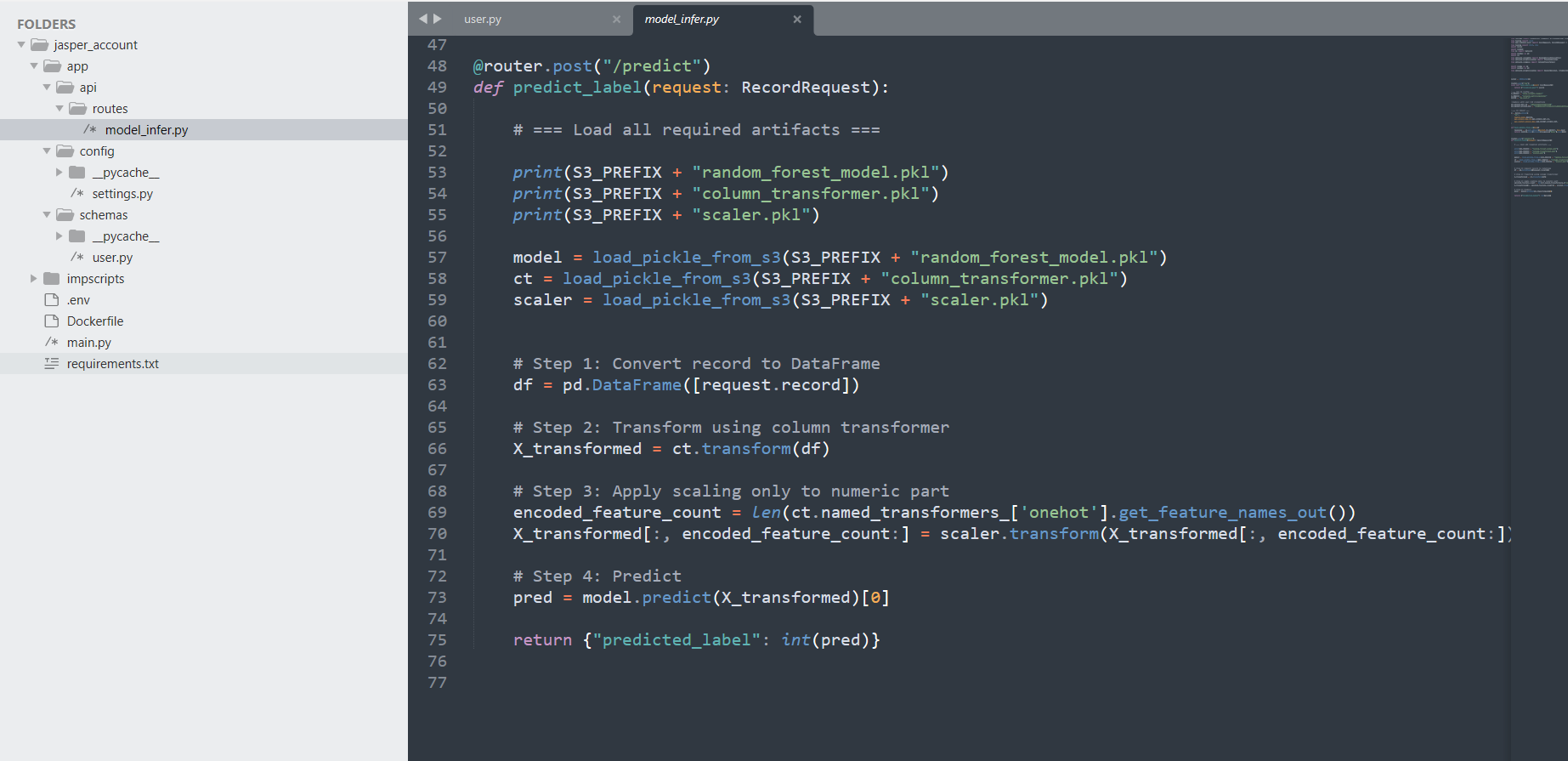
Production-Grade Inference API
Modular FastAPI app with strict Pydantic validation and separation of concerns between API routes and model inference logic. Serves a Random Forest model trained on flow metadata; models are versioned and served via a lightweight container. Health checks and structured JSON responses make the API production-ready.
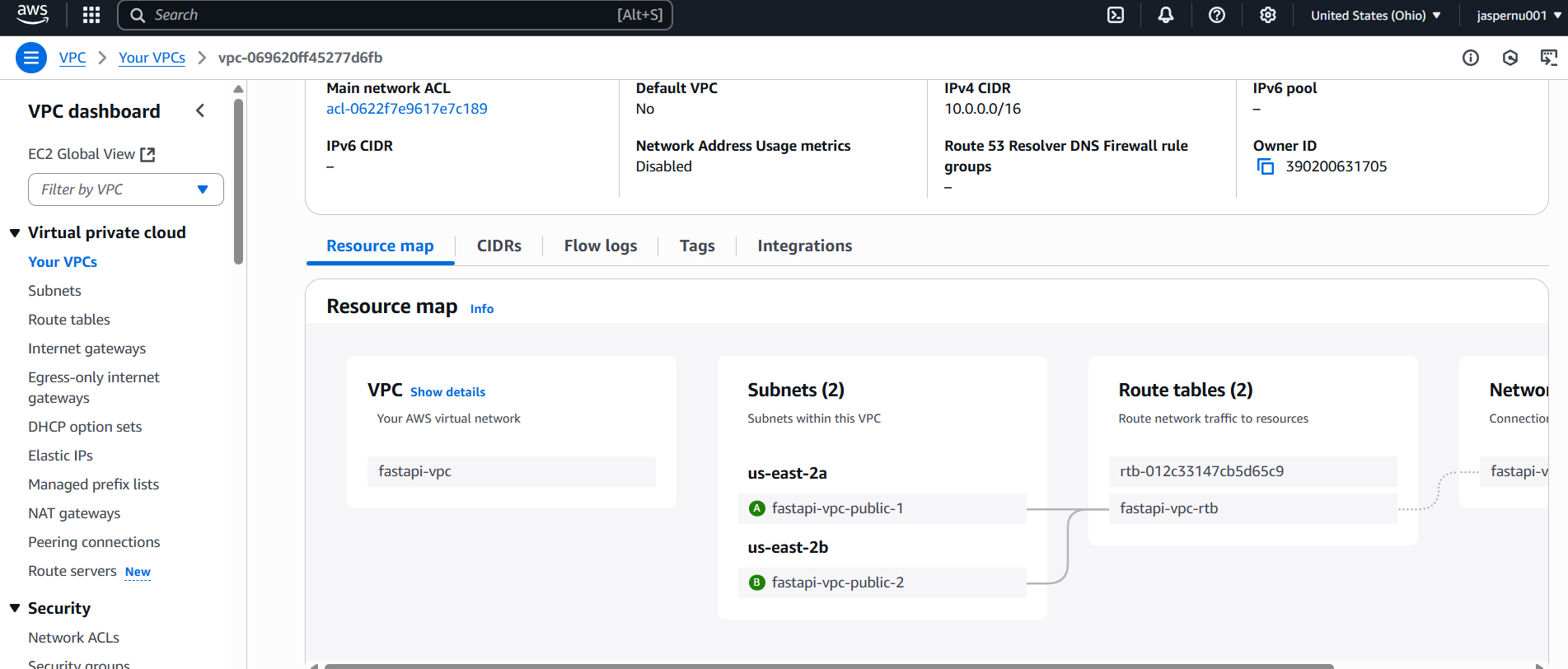
Network Security & VPC Configuration
Challenge: Enabling secure private communication between AWS Glue and Redshift without exposing credentials or traffic to public internet.
Solution: Utilized VPC Interface and Gateway Endpoints to create a private network tunnel, allowing JDBC database traffic to flow securely between services without traversing the public internet. This architecture isolates data within private subnets and enforces IAM-based role assignments to eliminate the need for hardcoded AWS access keys.