Bank Customer Churn Prediction
Comparative analysis of machine learning models to identify at-risk customers and optimize retention strategies.
Executive Summary
Customer retention is a critical priority for financial institutions, as churn directly impacts long-term growth and revenue. This project evaluated five supervised machine learning models to predict customer churn using a dataset of 165,000 banking records.
Key Results: LightGBM emerged as the strongest model, achieving the highest Test Accuracy (86.54%) and AUC (0.8896). While the default model prioritized precision, a strategic adjustment to the decision threshold (0.25) significantly improved the identification of churners (Recall increased to 75%), allowing for more effective resource allocation in retention campaigns.
Exploratory Data Analysis (EDA)
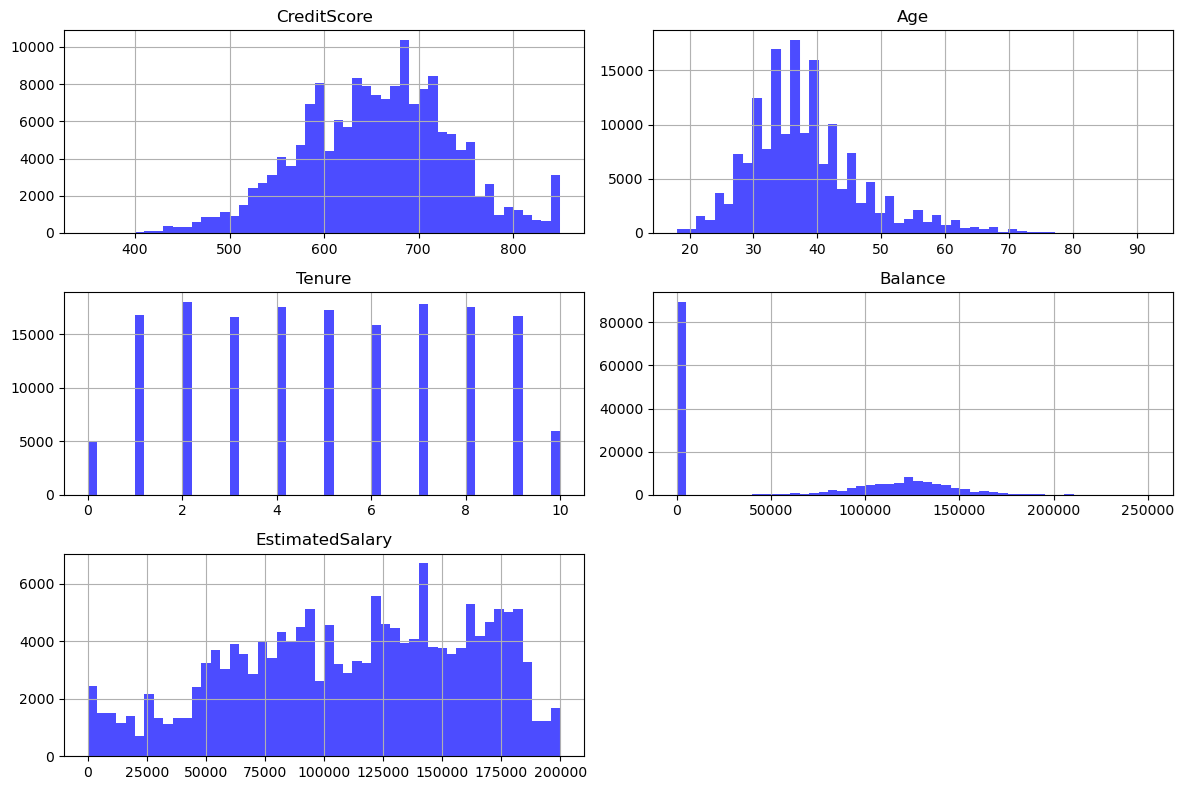
The dataset showed a moderate class imbalance, with 21% of customers having churned and 79% remaining. We identified several critical patterns during the analysis:
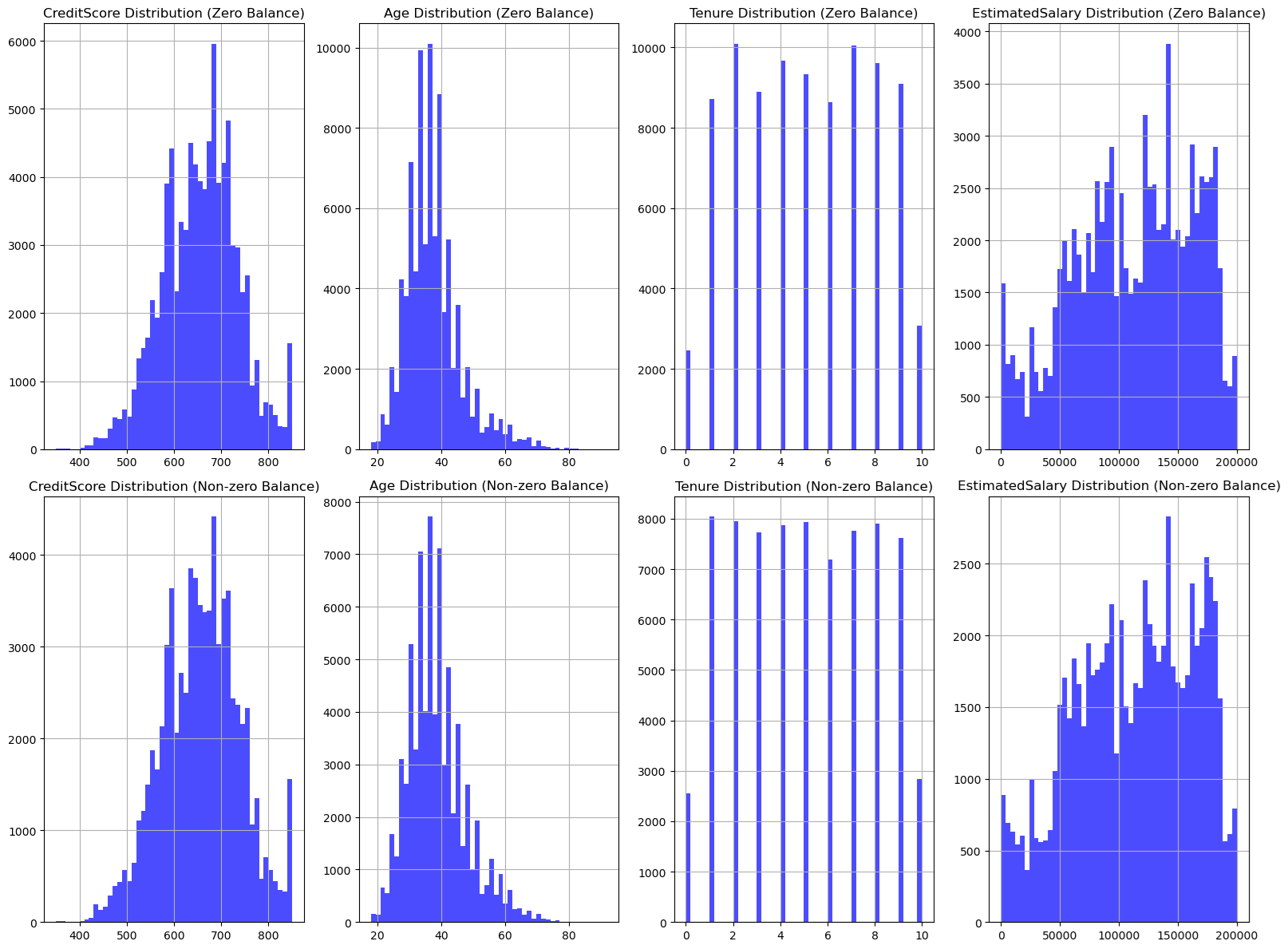
- The "Zero Balance" Anomaly: 54% of customers had a zero balance. Alarmingly, 83% of these zero-balance customers churned, compared to only 73% of non-zero balance customers.
- Geographic Disparities: 72% of zero-balance members resided in France, while the majority of non-zero balance members were from Germany.
- Age Factor: The age distribution was right-skewed (mean 38), and Age later proved to be a critical driver of churn behavior.
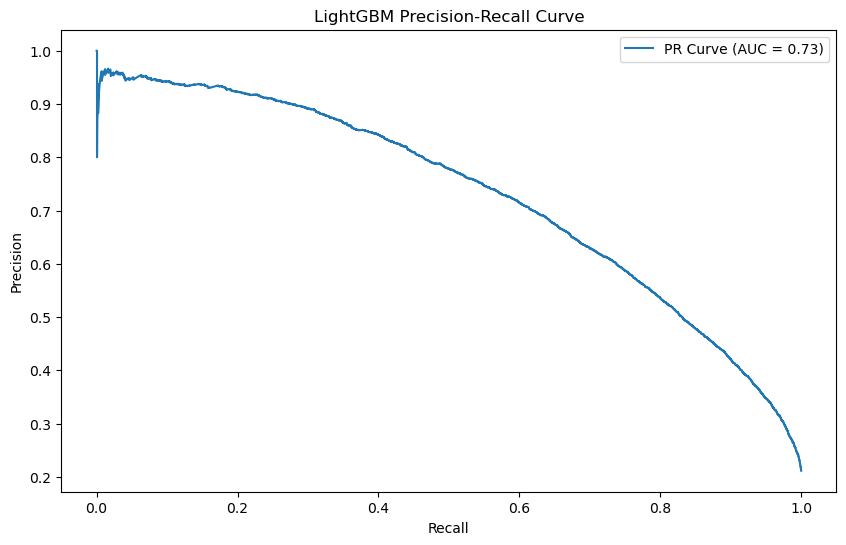
Model Performance & Comparisons
We implemented and optimized five distinct models: Logistic Regression, Random Forest, XGBoost, LightGBM, and a Neural Network. All numerical features were standardized, and categorical features were one-hot encoded.
1. Logistic Regression (Baseline)
The baseline model achieved a test accuracy of 85.51%. Feature selection attempts using ANOVA and Lasso did not yield significant improvements, confirming that the baseline configuration was robust. Feature importance analysis highlighted Age and Location (Germany) as top predictors.
2. Random Forest & XGBoost
Random Forest optimization revealed that performance stabilized after 100 trees. The optimized model (400 trees, max depth 10) achieved 86.51% accuracy. XGBoost delivered the highest F1-score (63.54%) despite a lower cross-validation accuracy, demonstrating strong capability in handling class imbalance.
3. LightGBM (Best Performer)
LightGBM was the overall strongest performer. Optimized via 5-fold cross-validation, it achieved the highest AUC (0.8896) and Test Accuracy (86.54%).
4. Neural Network
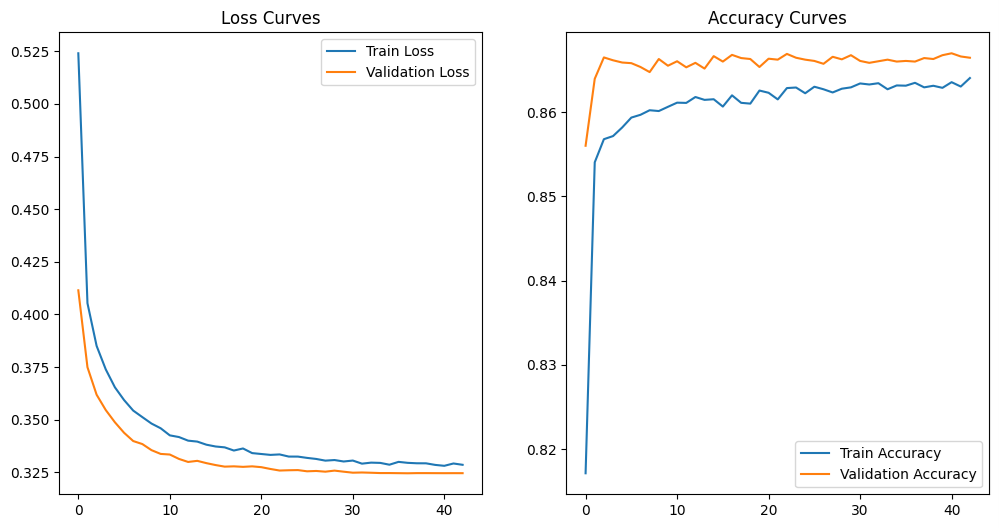
The Neural Network utilized a sequential architecture with 3 hidden layers (64-32-16 nodes), incorporating batch normalization and dropout to prevent overfitting. It achieved competitive accuracy (86.45%) but slightly lower recall than tree-based methods. Training was monitored with early stopping to ensure optimal convergence.
# Neural Network Architecture used for classification
model = Sequential([
Input(shape=(X_train.shape[1],)),
Dense(64, activation='relu', kernel_regularizer=l2(0.001)),
BatchNormalization(),
Dense(32, activation='relu', kernel_regularizer=l2(0.001)),
BatchNormalization(),
Dense(16, activation='relu', kernel_regularizer=l2(0.001)),
BatchNormalization(),
Dense(1, activation='sigmoid')
])
Performance Summary
| Model | Test Accuracy | F1-Score | AUC |
|---|---|---|---|
| Logistic Regression | 85.51% | 59.96% | 0.8697 |
| Random Forest | 86.51% | 62.07% | 0.8892 |
| Neural Network | 86.45% | 62.93% | 0.8879 |
| LightGBM | 86.54% | 63.44% | 0.8896 |
| XGBoost | 84.28% | 63.54% | 0.8842 |
Table 4: Summary of Model Performance.
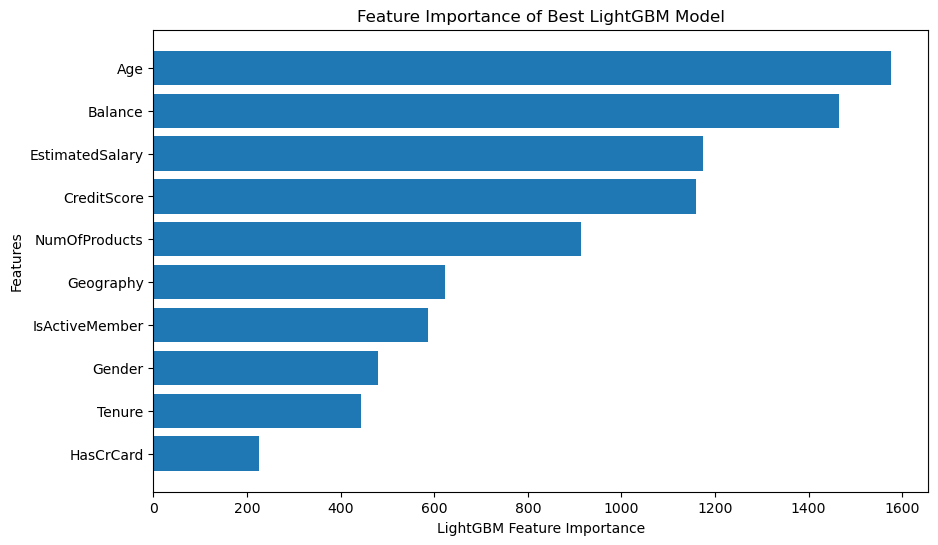
Feature Importance & Key Drivers
Understanding why customers leave is just as important as predicting who will leave. We analyzed feature importance across Logistic Regression, Random Forest, and LightGBM models, finding consistent patterns in customer behavior.
Key Findings:
- Age is Critical: Age consistently emerged as the dominant predictor across all models, suggesting older customers are more likely to churn.
- Financial Metrics Matter: Balance and Estimated Salary were top predictors in the Random Forest and LightGBM models.
- Product Usage: The number of bank products held was a strong influence in the Logistic Regression and LightGBM models.
Business Insights & Retention Strategy
While LightGBM had high accuracy, its initial recall was only 55.21%, meaning it missed nearly half of the actual churners. From a business perspective, missing a churner is more costly than falsely flagging a loyal customer.
Strategic Threshold Tuning
We lowered the classification threshold to 0.25. This strategic adjustment improved recall from 55% to 75%. While precision dropped, this trade-off allows the bank to capture a significantly larger portion of at-risk customers for intervention.
Recommendations
- Target Zero-Balance Accounts: Implement re-engagement offers for zero-balance customers in France, a high-risk segment.
- Age-Based Retention: Leverage the model's finding that Age is a key predictor by creating generationally tailored retention programs.
- Tiered Intervention: Use the probability scores to offer premium retention packages to high-probability churners and lighter-touch engagement for moderate risks.